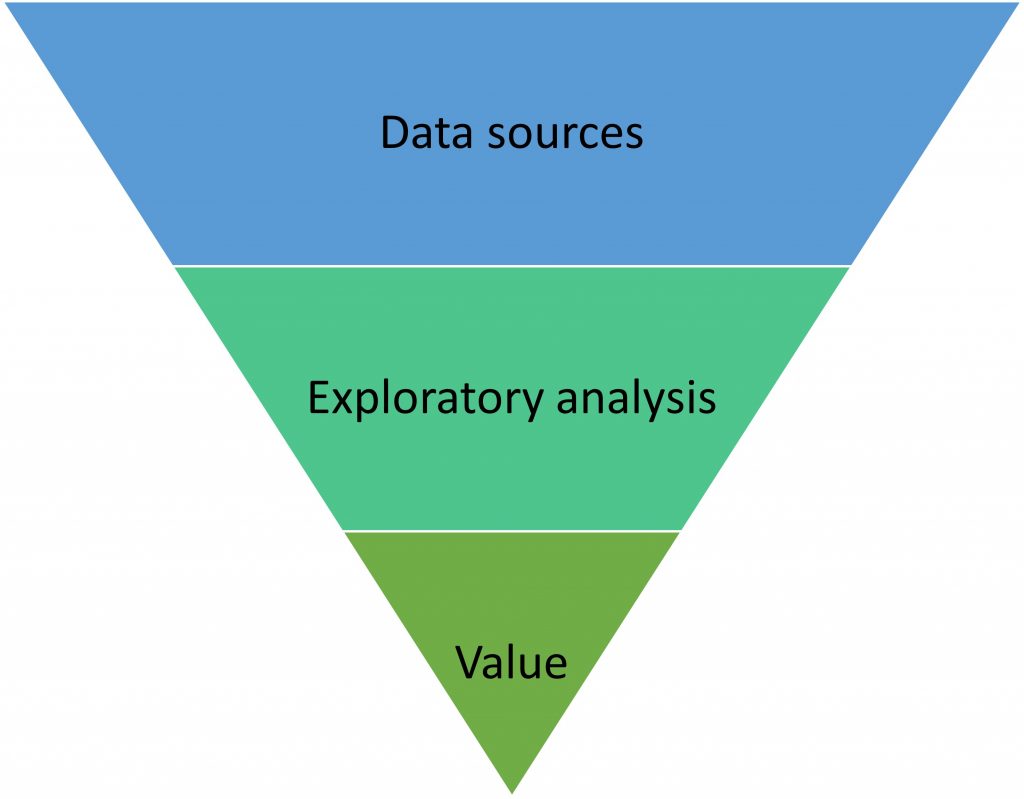
Datan arvo voidaan lunastaa vasta huolellisen käsittelyn ja kokeilevan analyysin kautta. Tämä vaatii kuitenkin jatkuvaa yhteistyötä data-analyytikkojen ja datan luovuttavien sidosryhmien kanssa.
Tässä blogissa keskitymme tiedon käsittelyn alkuvaiheisiin. InnoSale projektin luomassa blogisarjassa esitellään eri näkökulmia tietojen saatavuudesta tekoälylähtöisessä B2B-myynnissä käyttötapauksista (osa I), sidosryhmistä (osa II), datan jalostamisesta (osa III), tekoälymallien luottamuksellisuudesta (osa IV) ja liiketoiminnan hyödyistä (osa V), joka päättää blogisarjan. Blogeissa yritykset jakavat kokemuksiaan ja tavoitteitaan tekoälyn hyödyntämiseen liittyen. Blogisarja löytyy osoitteesta https://www.innosale.eu/. Tervetuloa myös webinaariin, joka pidetään 29.5.2024 14:00-15:30 Suomen aikaa, rekisteröitymislinkki tässä.